
Using the Vision API with Python
About this codelab
subjectLast updated Apr 4, 2023
account_circleWritten by multiple Googlers
1. Overview
The Vision API allows developers to easily integrate vision detection features within applications, including image labeling, face and landmark detection, optical character recognition (OCR), and tagging of explicit content.
In this tutorial, you will focus on using the Vision API with Python.
What you'll learn
How to set up your environment
How to perform label detection
How to perform text detection
How to perform landmark detection
How to perform face detection
How to perform object detection
What you'll need
2. Setup and requirements
Self-paced environment setup
Sign-in to the Google Cloud Console and create a new project or reuse an existing one. If you don't already have a Gmail or Google Workspace account, you must create one.

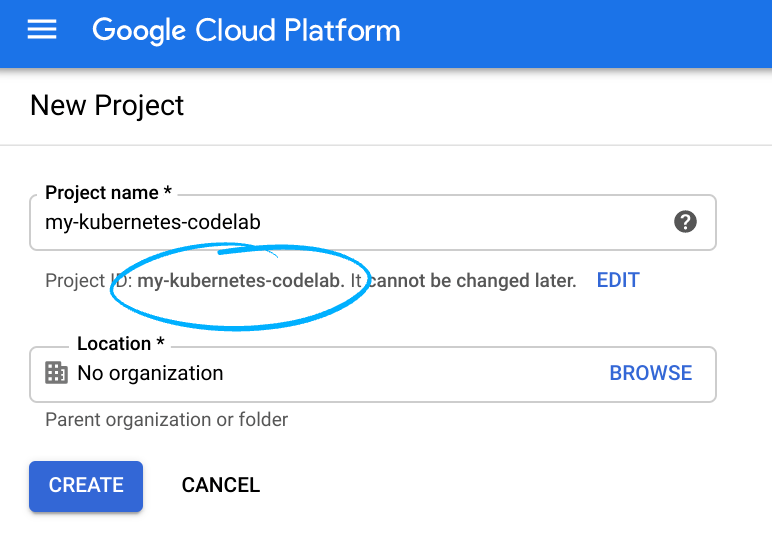
The Project name is the display name for this project's participants. It is a character string not used by Google APIs. You can always update it.
The Project ID is unique across all Google Cloud projects and is immutable (cannot be changed after it has been set). The Cloud Console auto-generates a unique string; usually you don't care what it is. In most codelabs, you'll need to reference your Project ID (typically identified as PROJECT_ID). If you don't like the generated ID, you might generate another random one. Alternatively, you can try your own, and see if it's available. It can't be changed after this step and remains for the duration of the project.
For your information, there is a third value, a Project Number, which some APIs use. Learn more about all three of these values in the documentation.
Caution: A project ID is globally unique and can't be used by anyone else after you've selected it. You are the only user of that ID. Even if a project is deleted, the ID can't be used again
Note: If you use a Gmail account, you can leave the default location set to No organization. If you use a Google Workspace account, choose a location that makes sense for your organization.
Next, you'll need to enable billing in the Cloud Console to use Cloud resources/APIs. Running through this codelab won't cost much, if anything at all. To shut down resources to avoid incurring billing beyond this tutorial, you can delete the resources you created or delete the project. New Google Cloud users are eligible for the $300 USD Free Trial program.
Start Cloud Shell
While Google Cloud can be operated remotely from your laptop, in this codelab you will be using Cloud Shell, a command line environment running in the Cloud.
Activate Cloud Shell
From the Cloud Console, click Activate Cloud Shell .


If this is your first time starting Cloud Shell, you're presented with an intermediate screen describing what it is. If you were presented with an intermediate screen, click Continue.
It should only take a few moments to provision and connect to Cloud Shell.

This virtual machine is loaded with all the development tools needed. It offers a persistent 5 GB home directory and runs in Google Cloud, greatly enhancing network performance and authentication. Much, if not all, of your work in this codelab can be done with a browser.
Once connected to Cloud Shell, you should see that you are authenticated and that the project is set to your project ID.
Run the following command in Cloud Shell to confirm that you are authenticated:
gcloud auth list
Command output
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Note: The gcloud command-line tool is the powerful and unified command-line tool in Google Cloud. It comes preinstalled in Cloud Shell. You will notice its support for tab completion. For more information, see gcloud command-line tool overview.
Run the following command in Cloud Shell to confirm that the gcloud command knows about your project:
gcloud config list project
Command output
[core]
project = <PROJECT_ID>
If it is not, you can set it with this command:
gcloud config set project <PROJECT_ID>
Command output
Updated property [core/project].
Note: If you're completing this tutorial outside of Cloud Shell, follow Set up Application Default Credentials.
3. Environment setup
Before you can begin using the Vision API, run the following command in Cloud Shell to enable the API:
gcloud services enable vision.googleapis.com
You should see something like this:
Operation "operations/..." finished successfully.
Now, you can use the Vision API!
Navigate to your home directory:
cd ~
Create a Python virtual environment to isolate the dependencies:
virtualenv venv-vision
Activate the virtual environment:
source venv-vision/bin/activate
Note: To stop using the virtual environment and go back to your system Python version, you can use the deactivate command.
Install IPython and the Vision API client library:
pip install ipython google-cloud-vision
You should see something like this:
...
Installing collected packages: ..., ipython, google-cloud-vision
Successfully installed ... google-cloud-vision-3.4.0 ...
Now, you're ready to use the Vision API client library!
Note: If you're setting up your own Python development environment outside of Cloud Shell, you can follow these guidelines.
In the next steps, you'll use an interactive Python interpreter called IPython, which you installed in the previous step. Start a session by running ipython in Cloud Shell:
ipython
You should see something like this:
Python 3.9.2 (default, Feb 28 2021, 17:03:44)
Type 'copyright', 'credits' or 'license' for more information
IPython 8.12.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
Note: If needed, you can quit your IPython session with the exit command.
You're ready to make your first request...
4. Perform label detection
One of the Vision API core features is to identify objects or entities in an image, known as label annotation. Label detection identifies general objects, locations, activities, animal species, products, and more. The Vision API takes an input image and returns the most likely labels which apply to that image. It returns the top-matching labels along with a confidence score of a match to the image.
In this example, you will perform label detection on an image (courtesy of Alex Knight) of Setagaya, a popular district in Tokyo:

Copy the following code into your IPython session:
==================================================================
from typing import Sequence
from google.cloud import vision
def analyze_image_from_uri(
image_uri: str,
feature_types: Sequence,
) -> vision.AnnotateImageResponse:
client = vision.ImageAnnotatorClient()
image = vision.Image()
image.source.image_uri = image_uri
features = [vision.Feature(type_=feature_type) for feature_type in feature_types]
request = vision.AnnotateImageRequest(image=image, features=features)
response = client.annotate_image(request=request)
return response
def print_labels(response: vision.AnnotateImageResponse):
print("=" * 80)
for label in response.label_annotations:
print(
f"{label.score:4.0%}",
f"{label.description:5}",
sep=" | ",
)
==============================================================================
Take a moment to study the code and see how it uses the annotate_image client library method to analyze an image for a set of given features.
Send a request with the LABEL_DETECTION feature:
==============================================================================
image_uri = "gs://cloud-samples-data/vision/label/setagaya.jpeg"
features = [vision.Feature.Type.LABEL_DETECTION]
response = analyze_image_from_uri(image_uri, features)
print_labels(response)
===========================================================================
You should get the following output:
================================================================================
97% | Bicycle
96% | Tire
94% | Wheel
91% | Automotive lighting
89% | Infrastructure
87% | Bicycle wheel
86% | Mode of transport
85% | Building
83% | Electricity
82% | Neighbourhood
If you get a PermissionDenied error, type exit to quit IPython, and return to the Setup and requirements step.
Here is how the results are presented by the online demo:

Summary
In this step, you were able to perform label detection on an image and display the most likely labels associated with that image. Read more about label detection.
Welcome to Cloud Shell! Type "help" to get started.
Your Cloud Platform project in this session is set to vision-api-383500.
Use “gcloud config set project [PROJECT_ID]” to change to a different project.
admin_@cloudshell:~ (vision-api-383500)$ gcloud auth list
Credentialed Accounts
ACTIVE: *
ACCOUNT: admin@uconnstamforddsc.org
To set the active account, run:
$ gcloud config set account `ACCOUNT`
admin_@cloudshell:~ (vision-api-383500)$ gcloud config list project
[core]
project = vision-api-383500
Your active configuration is: [cloudshell-11919]
admin_@cloudshell:~ (vision-api-383500)$ gcloud services enable vision.googleapis.com
Operation "operations/acat.p2-592102491226-513d08a3-0626-471b-94e4-3ca1b4bd4e3c" finished successfully.
admin_@cloudshell:~ (vision-api-383500)$ ^C
admin_@cloudshell:~ (vision-api-383500)$ virtualenv venv-vision
created virtual environment CPython3.9.2.final.0-64 in 655ms
creator CPython3Posix(dest=/home/admin_/venv-vision, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/home/admin_/.local/share/virtualenv)
added seed packages: pip==23.0.1, setuptools==67.4.0, wheel==0.38.4
activators BashActivator,CShellActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
admin_@cloudshell:~ (vision-api-383500)$ ^C
admin_@cloudshell:~ (vision-api-383500)$ source venv-vision/bin/activate
(venv-vision) admin_@cloudshell:~ (vision-api-383500)$ pip install ipython google-cloud-vision
Collecting ipython
Downloading ipython-8.12.0-py3-none-any.whl (796 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 796.4/796.4 kB 12.7 MB/s eta 0:00:00
Collecting google-cloud-vision
Using cached google_cloud_vision-3.4.1-py2.py3-none-any.whl (444 kB)
Collecting prompt-toolkit!=3.0.37,<3.1.0,>=3.0.30
Downloading prompt_toolkit-3.0.38-py3-none-any.whl (385 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 385.8/385.8 kB 26.7 MB/s eta 0:00:00
Collecting stack-data
Downloading stack_data-0.6.2-py3-none-any.whl (24 kB)
Collecting pygments>=2.4.0
Downloading Pygments-2.15.0-py3-none-any.whl (1.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 46.0 MB/s eta 0:00:00
Collecting typing-extensions
Downloading typing_extensions-4.5.0-py3-none-any.whl (27 kB)
Collecting jedi>=0.16
Downloading jedi-0.18.2-py2.py3-none-any.whl (1.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 48.7 MB/s eta 0:00:00
Collecting backcall
Downloading backcall-0.2.0-py2.py3-none-any.whl (11 kB)
Collecting traitlets>=5
Downloading traitlets-5.9.0-py3-none-any.whl (117 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 117.4/117.4 kB 12.9 MB/s eta 0:00:00
Collecting pickleshare
Downloading pickleshare-0.7.5-py2.py3-none-any.whl (6.9 kB)
Collecting pexpect>4.3
Downloading pexpect-4.8.0-py2.py3-none-any.whl (59 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 59.0/59.0 kB 5.6 MB/s eta 0:00:00
Collecting matplotlib-inline
Downloading matplotlib_inline-0.1.6-py3-none-any.whl (9.4 kB)
Collecting decorator
Downloading decorator-5.1.1-py3-none-any.whl (9.1 kB)
Collecting protobuf!=3.20.0,!=3.20.1,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<5.0.0dev,>=3.19.5
Downloading protobuf-4.22.1-cp37-abi3-manylinux2014_x86_64.whl (302 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 302.4/302.4 kB 27.9 MB/s eta 0:00:00
Collecting proto-plus<2.0.0dev,>=1.22.0
Downloading proto_plus-1.22.2-py3-none-any.whl (47 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 47.9/47.9 kB 5.6 MB/s eta 0:00:00
Collecting google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.10.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,!=2.8.*,!=2.9.*,<3.0.0dev,>=1.34.0
Downloading google_api_core-2.11.0-py3-none-any.whl (120 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 120.3/120.3 kB 11.9 MB/s eta 0:00:00
Collecting googleapis-common-protos<2.0dev,>=1.56.2
Downloading googleapis_common_protos-1.59.0-py2.py3-none-any.whl (223 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 223.6/223.6 kB 20.7 MB/s eta 0:00:00
Collecting google-auth<3.0dev,>=2.14.1
Downloading google_auth-2.17.2-py2.py3-none-any.whl (178 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 178.2/178.2 kB 18.6 MB/s eta 0:00:00
Collecting requests<3.0.0dev,>=2.18.0
Downloading requests-2.28.2-py3-none-any.whl (62 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 62.8/62.8 kB 7.9 MB/s eta 0:00:00
Collecting grpcio-status<2.0dev,>=1.33.2
Downloading grpcio_status-1.53.0-py3-none-any.whl (5.1 kB)
Collecting grpcio<2.0dev,>=1.33.2
Downloading grpcio-1.53.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (5.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.0/5.0 MB 66.5 MB/s eta 0:00:00
Collecting parso<0.9.0,>=0.8.0
Downloading parso-0.8.3-py2.py3-none-any.whl (100 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.8/100.8 kB 12.2 MB/s eta 0:00:00
Collecting ptyprocess>=0.5
Downloading ptyprocess-0.7.0-py2.py3-none-any.whl (13 kB)
Collecting wcwidth
Downloading wcwidth-0.2.6-py2.py3-none-any.whl (29 kB)
Collecting asttokens>=2.1.0
Downloading asttokens-2.2.1-py2.py3-none-any.whl (26 kB)
Collecting executing>=1.2.0
Downloading executing-1.2.0-py2.py3-none-any.whl (24 kB)
Collecting pure-eval
Downloading pure_eval-0.2.2-py3-none-any.whl (11 kB)
Collecting six
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Collecting pyasn1-modules>=0.2.1
Downloading pyasn1_modules-0.2.8-py2.py3-none-any.whl (155 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 155.3/155.3 kB 18.0 MB/s eta 0:00:00
Collecting cachetools<6.0,>=2.0.0
Downloading cachetools-5.3.0-py3-none-any.whl (9.3 kB)
Collecting rsa<5,>=3.1.4
Downloading rsa-4.9-py3-none-any.whl (34 kB)
Collecting idna<4,>=2.5
Downloading idna-3.4-py3-none-any.whl (61 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 61.5/61.5 kB 9.1 MB/s eta 0:00:00
Collecting urllib3<1.27,>=1.21.1
Downloading urllib3-1.26.15-py2.py3-none-any.whl (140 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 140.9/140.9 kB 17.1 MB/s eta 0:00:00
Collecting charset-normalizer<4,>=2
Downloading charset_normalizer-3.1.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (199 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 199.2/199.2 kB 20.2 MB/s eta 0:00:00
Collecting certifi>=2017.4.17
Downloading certifi-2022.12.7-py3-none-any.whl (155 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 155.3/155.3 kB 18.0 MB/s eta 0:00:00
Collecting pyasn1<0.5.0,>=0.4.6
Downloading pyasn1-0.4.8-py2.py3-none-any.whl (77 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.1/77.1 kB 9.5 MB/s eta 0:00:00
Installing collected packages: wcwidth, pyasn1, pure-eval, ptyprocess, pickleshare, executing, backcall, urllib3, typing-extensions, traitlets, six, rsa, pygments, pyasn1-modules, protobuf, prompt-toolkit, pexpect, parso, idna, grpcio, decorator, charset-normalizer, certifi, cachetools, requests, proto-plus, matplotlib-inline, jedi, googleapis-common-protos, google-auth, asttokens, stack-data, grpcio-status, google-api-core, ipython, google-cloud-vision
Successfully installed asttokens-2.2.1 backcall-0.2.0 cachetools-5.3.0 certifi-2022.12.7 charset-normalizer-3.1.0 decorator-5.1.1 executing-1.2.0 google-api-core-2.11.0 google-auth-2.17.2 google-cloud-vision-3.4.1 googleapis-common-protos-1.59.0 grpcio-1.53.0 grpcio-status-1.53.0 idna-3.4 ipython-8.12.0 jedi-0.18.2 matplotlib-inline-0.1.6 parso-0.8.3 pexpect-4.8.0 pickleshare-0.7.5 prompt-toolkit-3.0.38 proto-plus-1.22.2 protobuf-4.22.1 ptyprocess-0.7.0 pure-eval-0.2.2 pyasn1-0.4.8 pyasn1-modules-0.2.8 pygments-2.15.0 requests-2.28.2 rsa-4.9 six-1.16.0 stack-data-0.6.2 traitlets-5.9.0 typing-extensions-4.5.0 urllib3-1.26.15 wcwidth-0.2.6
(venv-vision) admin_@cloudshell:~ (vision-api-383500)$ ipython
Python 3.9.2 (default, Feb 28 2021, 17:03:44)
Type 'copyright', 'credits' or 'license' for more information
IPython 8.12.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: from typing import Sequence
...:
...: from google.cloud import vision
...:
...:
...: def analyze_image_from_uri(
...: image_uri: str,
...: feature_types: Sequence,
...: ) -> vision.AnnotateImageResponse:
...: client = vision.ImageAnnotatorClient()
...:
...: image = vision.Image()
...: image.source.image_uri = image_uri
...: features = [vision.Feature(type_=feature_type) for feature_type in feature_types]
...: request = vision.AnnotateImageRequest(image=image, features=features)
...:
...: response = client.annotate_image(request=request)
...:
...: return response
...:
...:
...: def print_labels(response: vision.AnnotateImageResponse):
...: print("=" * 80)
...: for label in response.label_annotations:
...: print(
...: f"{label.score:4.0%}",
...: f"{label.description:5}",
...: sep=" | ",
...: )
...:
In [2]: image_uri = "gs://cloud-samples-data/vision/label/setagaya.jpeg"
...: features = [vision.Feature.Type.LABEL_DETECTION]
...:
...: response = analyze_image_from_uri(image_uri, features)
...: print_labels(response)
================================================================================
97% | Bicycle
96% | Tire
94% | Wheel
91% | Automotive lighting
89% | Infrastructure
87% | Bicycle wheel
86% | Mode of transport
85% | Building
83% | Electricity
82% | Neighbourhood
In [3]:
5. Perform text detection
Text detection performs Optical Character Recognition (OCR). It detects and extracts text within an image with support for a broad range of languages. It also features automatic language identification.
In this example, you will perform text detection on a traffic sign image:

Copy the following code into your IPython session:
=======================================================================
def print_text(response: vision.AnnotateImageResponse):
print("=" * 80)
for annotation in response.text_annotations:
vertices = [f"({v.x},{v.y})" for v in annotation.bounding_poly.vertices]
print(
f"{repr(annotation.description):42}",
",".join(vertices),
sep=" | ",
)
=======================================================================
Send a request with the TEXT_DETECTION feature:
=========================================================================
image_uri = "gs://cloud-samples-data/vision/ocr/sign.jpg"
features = [vision.Feature.Type.TEXT_DETECTION]
response = analyze_image_from_uri(image_uri, features)
print_text(response)
=============================================================================
You should get the following output:
Note replace the public image with your own image from your cloud storage bucket
e.g.
image_uri = "gs://uconn-images/National-Champs-MBB.jpg" features = [vision.Feature.Type.TEXT_DETECTION] response = analyze_image_from_uri(image_uri, features) print_text(response)
================================================================================
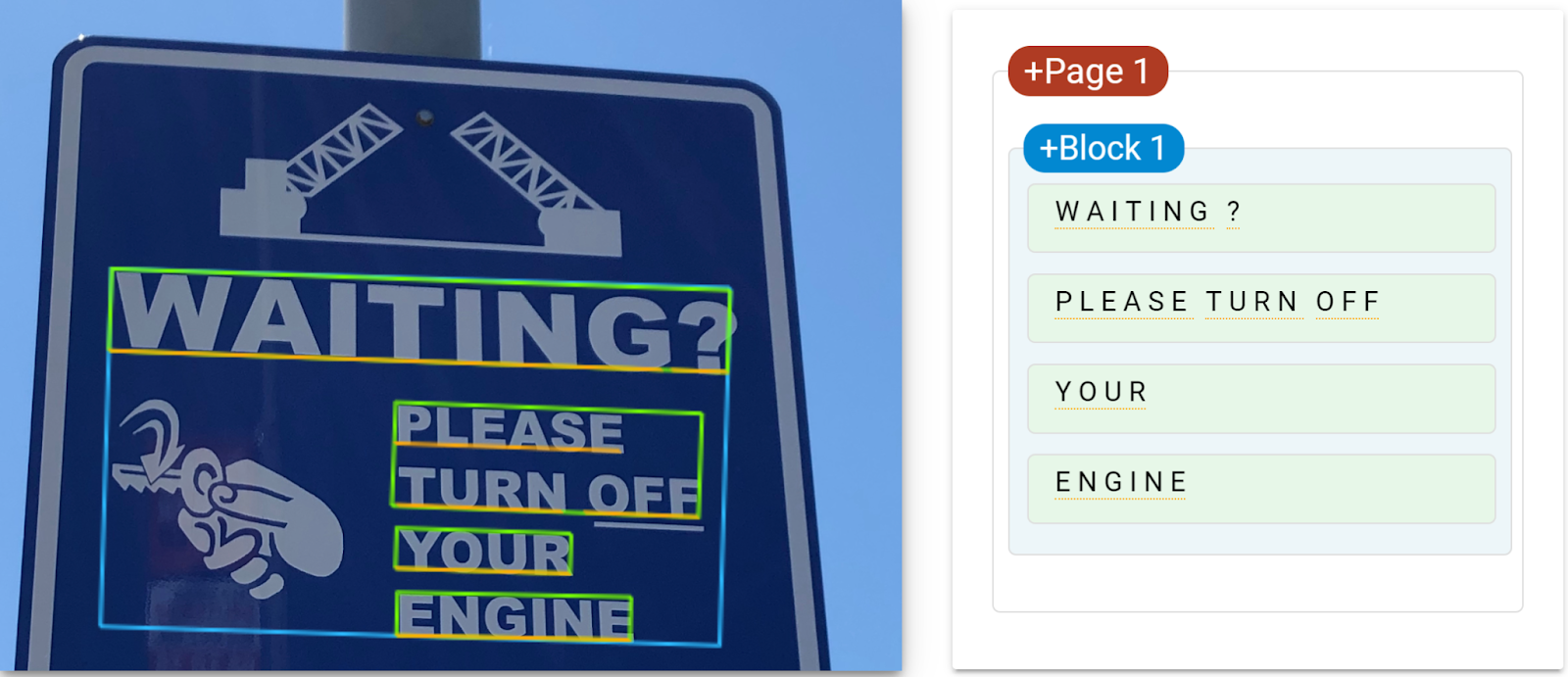
'WAITING?\nPLEASE\nTURN OFF\nYOUR\nENGINE' | (310,821),(2225,821),(2225,1965),(310,1965)
'WAITING' | (344,821),(2025,879),(2016,1127),(335,1069)
'?' | (2057,881),(2225,887),(2216,1134),(2048,1128)
'PLEASE' | (1208,1230),(1895,1253),(1891,1374),(1204,1351)
'TURN' | (1217,1414),(1718,1434),(1713,1558),(1212,1538)
'OFF' | (1787,1437),(2133,1451),(2128,1575),(1782,1561)
'YOUR' | (1211,1609),(1741,1626),(1737,1747),(1207,1731)
'ENGINE' | (1213,1805),(1923,1819),(1920,1949),(1210,1935)
Here is how the results are presented by the online demo:
Summary
In this step, you were able to perform text detection on an image and display the recognized text from the image. Read more about text detection.
In [3]: def print_text(response: vision.AnnotateImageResponse):
...: print("=" * 80)
...: for annotation in response.text_annotations:
...: vertices = [f"({v.x},{v.y})" for v in annotation.bounding_poly.vertices]
...: print(
...: f"{repr(annotation.description):42}",
...: ",".join(vertices),
...: sep=" | ",
...: )
...:
In [4]: image_uri = "gs://cloud-samples-data/vision/ocr/sign.jpg"
...: features = [vision.Feature.Type.TEXT_DETECTION]
...:
...: response = analyze_image_from_uri(image_uri, features)
...: print_text(response)
================================================================================
'WAITING?\nPLEASE\nTURN OFF\nYOUR\nENGINE' | (310,821),(2225,821),(2225,1965),(310,1965)
'WAITING' | (344,821),(2025,879),(2016,1127),(335,1069)
'?' | (2057,881),(2225,887),(2216,1134),(2048,1128)
'PLEASE' | (1207,1231),(1895,1254),(1891,1374),(1203,1351)
'TURN' | (1217,1414),(1718,1434),(1712,1559),(1212,1539)
'OFF' | (1787,1437),(2133,1451),(2128,1576),(1782,1562)
'YOUR' | (1211,1609),(1741,1626),(1737,1748),(1207,1732)
'ENGINE' | (1214,1805),(1923,1819),(1920,1949),(1211,1935)
6. Perform landmark detection
Landmark detection detects popular natural and man-made structures within an image.
In this example, you will perform landmark detection on an image (courtesy of John Towner) of the Eiffel Tower:

Copy the following code into your IPython session:
===================================================================
def print_landmarks(response: vision.AnnotateImageResponse, min_score: float = 0.5):
print("=" * 80)
for landmark in response.landmark_annotations:
if landmark.score < min_score:
continue
vertices = [f"({v.x},{v.y})" for v in landmark.bounding_poly.vertices]
lat_lng = landmark.locations[0].lat_lng
print(
f"{landmark.description:18}",
",".join(vertices),
f"{lat_lng.latitude:.5f}",
f"{lat_lng.longitude:.5f}",
sep=" | ",
)
===============================================================
Send a request with the LANDMARK_DETECTION feature:
===============================================================
image_uri = "gs://cloud-samples-data/vision/landmark/eiffel_tower.jpg"
features = [vision.Feature.Type.LANDMARK_DETECTION]
response = analyze_image_from_uri(image_uri, features)
print_landmarks(response)
==============================
You should get the following output:
================================================================================
Trocadéro Gardens | (303,36),(520,36),(520,371),(303,371) | 48.86160 | 2.28928
Eiffel Tower | (458,76),(512,76),(512,263),(458,263) | 48.85846 | 2.29435
Here is how the results are presented by the online demo:

Summary
In this step, you were able to perform landmark detection on an image of the Eiffel Tower. Read more about landmark detection.
In [5]: def print_landmarks(response: vision.AnnotateImageResponse, min_score: float = 0.5):
...: print("=" * 80)
...: for landmark in response.landmark_annotations:
...: if landmark.score < min_score:
...: continue
...: vertices = [f"({v.x},{v.y})" for v in landmark.bounding_poly.vertices]
...: lat_lng = landmark.locations[0].lat_lng
...: print(
...: f"{landmark.description:18}",
...: ",".join(vertices),
...: f"{lat_lng.latitude:.5f}",
...: f"{lat_lng.longitude:.5f}",
...: sep=" | ",
...: )
...:
In [6]: image_uri = "gs://cloud-samples-data/vision/landmark/eiffel_tower.jpg"
...: features = [vision.Feature.Type.LANDMARK_DETECTION]
...:
...: response = analyze_image_from_uri(image_uri, features)
...: print_landmarks(response)
================================================================================
Champ De Mars | (0,0),(640,0),(640,426),(0,426) | 48.85565 | 2.29863
Pont De Bir-Hakeim | (0,0),(640,0),(640,426),(0,426) | 48.85560 | 2.28759
Eiffel Tower | (0,0),(640,0),(640,426),(0,426) | 48.85837 | 2.29448
7. Perform face detection
Facial features detection detects multiple faces within an image along with the associated key facial attributes such as emotional state or wearing headwear.
In this example, you will detect faces in the following picture (courtesy of Himanshu Singh Gurjar):

Copy the following code into your IPython session:
====================================================================
def print_faces(response: vision.AnnotateImageResponse):
print("=" * 80)
for face_number, face in enumerate(response.face_annotations, 1):
vertices = ",".join(f"({v.x},{v.y})" for v in face.bounding_poly.vertices)
print(f"# Face {face_number} @ {vertices}")
print(f"Joy: {face.joy_likelihood.name}")
print(f"Exposed: {face.under_exposed_likelihood.name}")
print(f"Blurred: {face.blurred_likelihood.name}")
print("-" * 80)
====================================================================
Send a request with the FACE_DETECTION feature:
===================================
image_uri = "gs://cloud-samples-data/vision/face/faces.jpeg"
features = [vision.Feature.Type.FACE_DETECTION]
response = analyze_image_from_uri(image_uri, features)
print_faces(response)
===========================================================================================
You should get the following output:
================================================================================
# Face 1 @ (1077,157),(2146,157),(2146,1399),(1077,1399)
Joy: VERY_LIKELY
Exposed: VERY_UNLIKELY
Blurred: VERY_UNLIKELY
--------------------------------------------------------------------------------
# Face 2 @ (144,1273),(793,1273),(793,1844),(144,1844)
Joy: VERY_UNLIKELY
Exposed: VERY_UNLIKELY
Blurred: UNLIKELY
--------------------------------------------------------------------------------
# Face 3 @ (785,167),(1100,167),(1100,534),(785,534)
Joy: VERY_UNLIKELY
Exposed: LIKELY
Blurred: VERY_LIKELY
--------------------------------------------------------------------------------
Here is how the results are presented by the online demo:
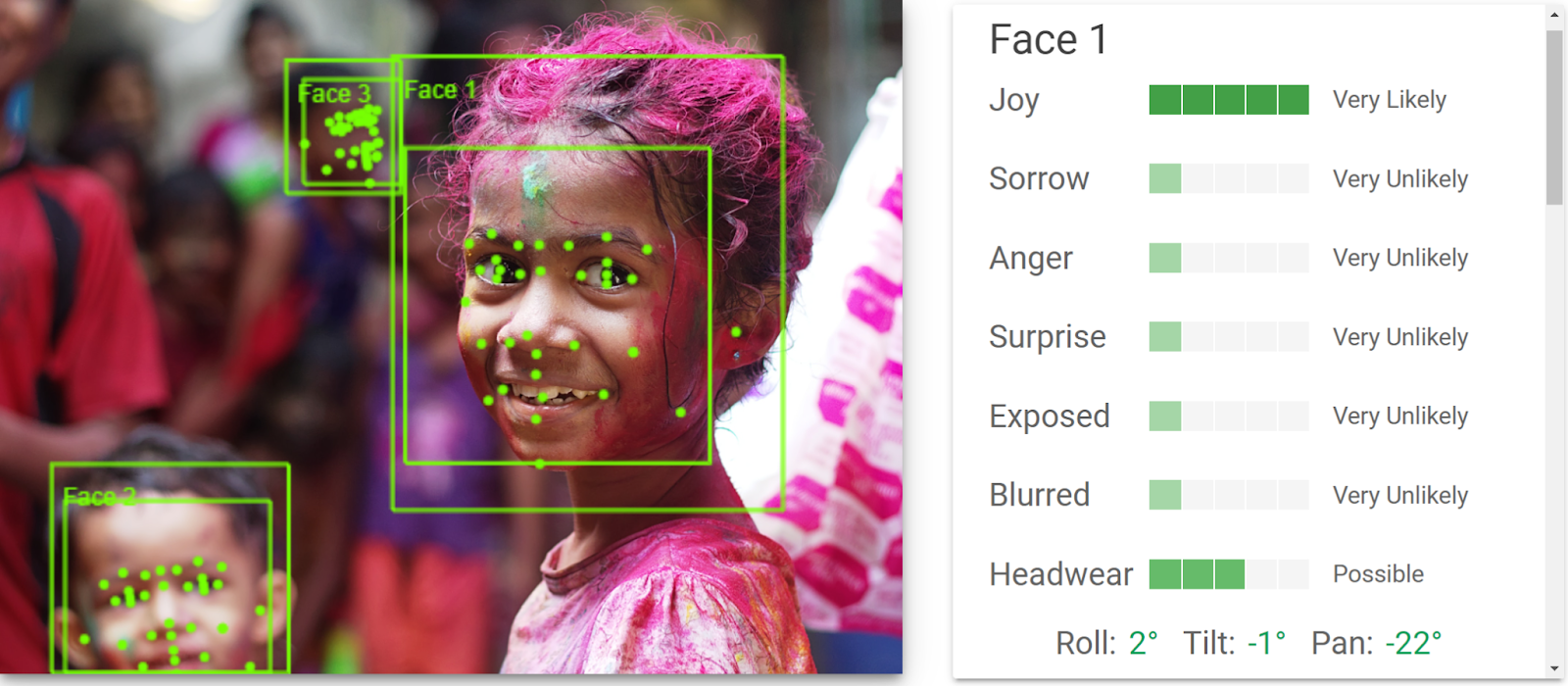
Summary
In this step, you were able to perform face detection. Read more about face detection.
In [10]: def print_faces(response: vision.AnnotateImageResponse):
...: print("=" * 80)
...: for face_number, face in enumerate(response.face_annotations, 1):
...: vertices = ",".join(f"({v.x},{v.y})" for v in face.bounding_poly.vertices)
...: print(f"# Face {face_number} @ {vertices}")
...: print(f"Joy: {face.joy_likelihood.name}")
...: print(f"Exposed: {face.under_exposed_likelihood.name}")
...: print(f"Blurred: {face.blurred_likelihood.name}")
...: print("-" * 80)
...:
In [13]: image_uri = "gs://cloud-samples-data/vision/face/faces.jpeg"
...: features = [vision.Feature.Type.FACE_DETECTION]
...:
...: response = analyze_image_from_uri(image_uri, features)
...: print_faces(response)
================================================================================
# Face 1 @ (664,28),(816,28),(816,205),(664,205)
Joy: VERY_UNLIKELY
Exposed: VERY_UNLIKELY
Blurred: VERY_UNLIKELY
--------------------------------------------------------------------------------
# Face 2 @ (784,170),(1097,170),(1097,534),(784,534)
Joy: VERY_UNLIKELY
Exposed: VERY_UNLIKELY
Blurred: VERY_UNLIKELY
--------------------------------------------------------------------------------
# Face 3 @ (1076,151),(2144,151),(2144,1392),(1076,1392)
Joy: VERY_LIKELY
Exposed: VERY_UNLIKELY
Blurred: VERY_UNLIKELY
--------------------------------------------------------------------------------
# Face 4 @ (143,1273),(793,1273),(793,1844),(143,1844)
Joy: VERY_UNLIKELY
Exposed: VERY_UNLIKELY
Blurred: VERY_UNLIKELY
-------------------------
8. Perform object detection
In this example, you will perform object detection on the same prior image (courtesy of Alex Knight) of Setagaya:

Copy the following code into your IPython session:
========================================================================
def print_objects(response: vision.AnnotateImageResponse):
print("=" * 80)
for obj in response.localized_object_annotations:
nvertices = obj.bounding_poly.normalized_vertices
print(
f"{obj.score:4.0%}",
f"{obj.name:15}",
f"{obj.mid:10}",
",".join(f"({v.x:.1f},{v.y:.1f})" for v in nvertices),
sep=" | ",
)
======================================================================
Send a request with the OBJECT_LOCALIZATION feature:
=======================================================================
image_uri = "gs://cloud-samples-data/vision/label/setagaya.jpeg"
features = [vision.Feature.Type.OBJECT_LOCALIZATION]
response = analyze_image_from_uri(image_uri, features)
print_objects(response)
=========================================================
You should get the following output:
================================================================================
93% | Bicycle | /m/0199g | (0.6,0.6),(0.8,0.6),(0.8,0.9),(0.6,0.9)
92% | Bicycle wheel | /m/01bqk0 | (0.6,0.7),(0.7,0.7),(0.7,0.9),(0.6,0.9)
91% | Tire | /m/0h9mv | (0.7,0.7),(0.8,0.7),(0.8,1.0),(0.7,1.0)
75% | Bicycle | /m/0199g | (0.3,0.6),(0.4,0.6),(0.4,0.7),(0.3,0.7)
51% | Tire | /m/0h9mv | (0.3,0.6),(0.4,0.6),(0.4,0.7),(0.3,0.7)
Here is how the results are presented by the online demo:

Summary
In this step, you were able to perform object detection. Read more about object detection.
In [14]:
In [14]: def print_objects(response: vision.AnnotateImageResponse):
...: print("=" * 80)
...: for obj in response.localized_object_annotations:
...: nvertices = obj.bounding_poly.normalized_vertices
...: print(
...: f"{obj.score:4.0%}",
...: f"{obj.name:15}",
...: f"{obj.mid:10}",
...: ",".join(f"({v.x:.1f},{v.y:.1f})" for v in nvertices),
...: sep=" | ",
...: )
...:
In [15]: image_uri = "gs://cloud-samples-data/vision/label/setagaya.jpeg"
...: features = [vision.Feature.Type.OBJECT_LOCALIZATION]
...:
...: response = analyze_image_from_uri(image_uri, features)
...: print_objects(response)
================================================================================
93% | Bicycle | /m/0199g | (0.6,0.6),(0.8,0.6),(0.8,0.9),(0.6,0.9)
92% | Bicycle wheel | /m/01bqk0 | (0.6,0.7),(0.7,0.7),(0.7,0.9),(0.6,0.9)
91% | Tire | /m/0h9mv | (0.7,0.7),(0.8,0.7),(0.8,1.0),(0.7,1.0)
75% | Bicycle | /m/0199g | (0.3,0.6),(0.4,0.6),(0.4,0.7),(0.3,0.7)
51% | Tire | /m/0h9mv | (0.3,0.6),(0.4,0.6),(0.4,0.7),(0.3,0.7)
In [16]:
9. Multiple features
You've seen how to use some features of the Vision API, but there are many more and you can request multiple features in a single request.
Here the kind of request you can make to get all insights at once:
image_uri = "gs://..."
features = [
vision.Feature.Type.OBJECT_LOCALIZATION,
vision.Feature.Type.FACE_DETECTION,
vision.Feature.Type.LANDMARK_DETECTION,
vision.Feature.Type.LOGO_DETECTION,
vision.Feature.Type.LABEL_DETECTION,
vision.Feature.Type.TEXT_DETECTION,
vision.Feature.Type.DOCUMENT_TEXT_DETECTION,
vision.Feature.Type.SAFE_SEARCH_DETECTION,
vision.Feature.Type.IMAGE_PROPERTIES,
vision.Feature.Type.CROP_HINTS,
vision.Feature.Type.WEB_DETECTION,
vision.Feature.Type.PRODUCT_SEARCH,
vision.Feature.Type.OBJECT_LOCALIZATION,
]
# response = analyze_image_from_uri(image_uri, features)
And there are more possibilities, like performing detections on a batch of images, synchronously or asynchronously. Check out all the how-to guides.
You learned how to use the Vision API with Python and tested a few image detection features!
Note: This codelab should not infer any cost. The Google Cloud Free Tier lets you analyze for free 1,000 images per feature every month. Learn more on the Vision pricing.
Clean up
To clean up your development environment, from Cloud Shell:
If you're still in your IPython session, go back to the shell: exit
Stop using the Python virtual environment: deactivate
Delete your virtual environment folder: cd ~ ; rm -rf ./venv-vision
To delete your Google Cloud project, from Cloud Shell:
Retrieve your current project ID: PROJECT_ID=$(gcloud config get-value core/project)
Make sure this is the project you want to delete: echo $PROJECT_ID
Delete the project: gcloud projects delete $PROJECT_ID
Learn More
Test the online demo in your browser: https://cloud.google.com/vision
Vision API documentation: https://cloud.google.com/vision/docs
Python on Google Cloud: https://cloud.google.com/python
Cloud Client Libraries for Python: https://github.com/googleapis/google-cloud-python
License
This work is licensed under a Creative Commons Attribution 2.0 Generic License.

No comments:
Post a Comment