
NLP Definitions
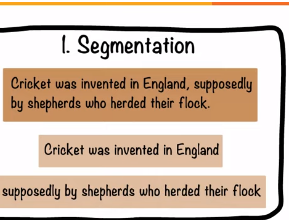
In NLP, segmenting a text document into its sentences is a useful basic operation. It is the first step in many NLP tasks that are more elaborate. Such as detecting and correcting errors in the text as it is being written or detecting named entities.
Natural Language Processing segmentation is the process of breaking down a large piece of text into smaller, more meaningful units, such as sentences or paragraphs. This process helps make the content easier to understand and analyze.
Segmentation is important for other NLP applications, such as: summarization, context understanding, question-answering, document indexing, and document noise removal
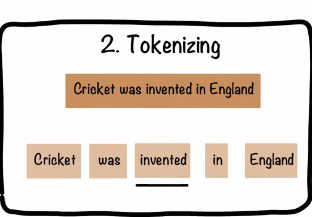
Tokenization is a term that describes breaking a document or body of text into small units called tokens. You can define tokens by certain character sequences, punctuation, or other definitions depending on the type of tokenization. Doing so makes it easier for a machine to process the text.
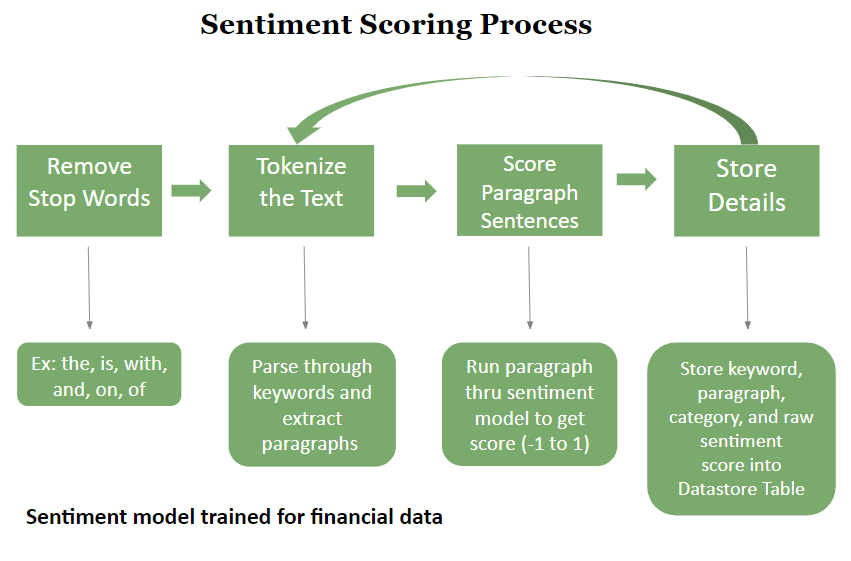
In Natural Language Processing (NLP), stop words are common words that are removed from text because they are considered to be of little value in understanding the meaning of a sentence.

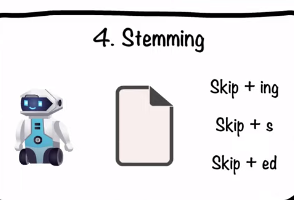
Stemming is a text preprocessing technique in natural language processing (NLP). Specifically, it is the process of reducing inflected form of a word to one so-called “stem,” or root form, also known as a “lemma” in linguistics.1 It is one of two primary methods—the other being lemmatization—that reduces inflectional variants within a text dataset to one morphological lexeme. In doing so, stemming aims to improve text processing in machine learning and information retrieval systems.
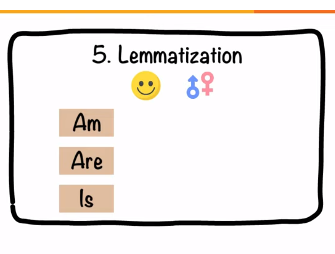
Lemmatization is a text pre-processing technique used in natural language processing (NLP) models to break a word down to its root meaning to identify similarities. For example, a lemmatization algorithm would reduce the word better to its root word, or lemme, good.
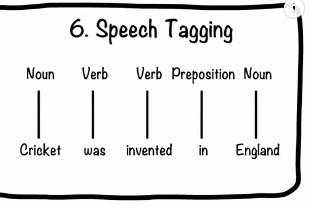
Part-of-speech (POS) tagging is a natural language processing (NLP) task that assigns words in a text with their corresponding part of speech. This process is also known as grammatical tagging or word-category disambiguation.
POS tagging is a fundamental step in NLP because it helps machines understand the meaning and grammatical structure of sentences. This makes it useful for many NLP tasks, including: information extraction, named entity recognition, machine translation, and sentiment analysis.
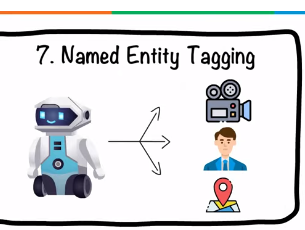
Named Entity Recognition (NER) is a sub-task of information extraction in Natural Language Processing (NLP) that classifies named entities into predefined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, and more.

No comments:
Post a Comment