
NLP Example Explained
Overview
In this codelab, you will focus on using the Natural Language API with Python. You will learn how to perform sentiment analysis, entity analysis,
syntax analysis, and content classification.
What you'll learn
How to use Cloud Shell
How to enable the Natural Language API
How to authenticate API requests
How to install the client library for Python
How to perform sentiment analysis
How to perform entity analysis
How to perform syntax analysis
How to perform content classification
What you'll need
2. Setup and requirements
Self-paced environment setup
Sign in to Cloud Console and create a new project or reuse an existing one. (If you don't already have a Gmail or G Suite account, you must create one.)
Note: You can easily access Cloud Console by memorizing its URL,
which is console.cloud.google.com.

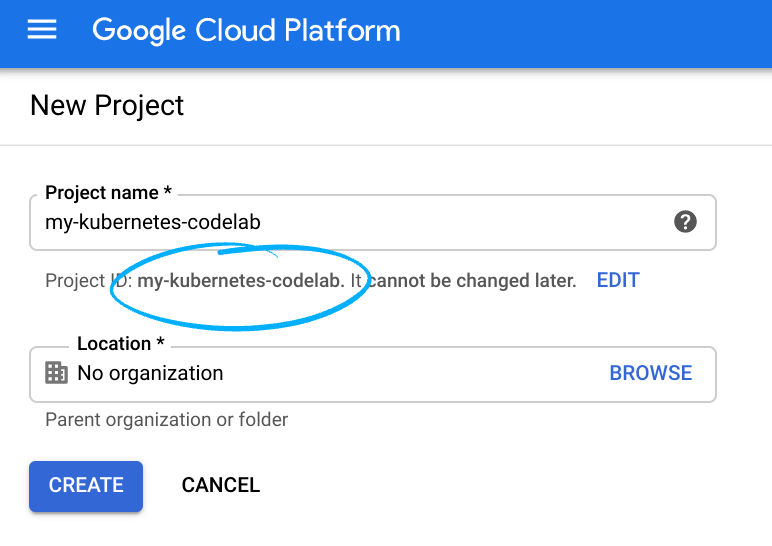
Remember the project ID, a unique name across all Google Cloud projects
(the name above has already been taken and will not work for you, sorry!).
It will be referred to later in this codelab as PROJECT_ID.
Note: If you're using a Gmail account, you can leave the default location set to
No organization. If you're using a G Suite account, then choose a location that
makes sense for your organization.
Next, you'll need to enable billing in Cloud Console in order to use Google Cloud resources.
Running through this codelab shouldn't cost much, if anything at all.
Be sure to to follow any instructions in the "Cleaning up" section which
advises you how to shut down resources so you don't incur billing beyond this tutorial.
New users of Google Cloud are eligible for the $300USD Free Trial program.
Start Cloud Shell
While Google Cloud can be operated remotely from your laptop,
in this codelab you will be using Cloud Shell, a command line environment running in the Cloud.
Activate Cloud Shell
From the Cloud Console, click Activate Cloud Shell .


If you've never started Cloud Shell before, you'll be presented with an
intermediate screen (below the fold) describing what it is.
If that's the case, click Continue (and you won't ever see it again).
Here's what that one-time screen looks like:
It should only take a few moments to provision and connect to Cloud Shell.

This virtual machine is loaded with all the development tools you'll need.
It offers a persistent 5GB home directory and runs in Google Cloud,
greatly enhancing network performance and authentication. Much,
if not all, of your work in this codelab can be done with simply a browser or your
Chromebook.
Once connected to Cloud Shell, you should see that you are already authenticated
and that the project is already set to your project ID.
2. Run the following command in Cloud Shell to confirm that you are authenticated:
gcloud auth list
Command output
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
john_iacovacci1@cloudshell:~ (uconn-engr)$ gcloud config list project
[core]
project = uconn-engr
Your active configuration is: [cloudshell-11917]
john_iacovacci1@cloudshell:~ (uconn-engr)$
Note: The gcloud command-line tool is the powerful and unified command-line tool in Google
Cloud. It comes preinstalled in Cloud Shell. You will notice its support for
tab completion. For more information, see gcloud command-line tool overview.
gcloud config list project
Command output
[core]
project = <PROJECT_ID>
If it is not, you can set it with this command:
gcloud config set project <PROJECT_ID>
Command output
Updated property [core/project].
3. Environment setup
Before you can begin using the Natural Language API, run the following
command in Cloud Shell to enable the API:
gcloud services enable language.googleapis.com
john_iacovacci1@cloudshell:~ (uconn-engr)$ gcloud services enable language.googleapis.com
john_iacovacci1@cloudshell:~ (uconn-engr)$
Now, you can use the Natural Language API!
Navigate to your home directory:
cd ~
mkdir nlp
john_iacovacci1@cloudshell:~ (uconn-engr)$ mkdir nlp
john_iacovacci1@cloudshell:~ (uconn-engr)$ cd nlp
john_iacovacci1@cloudshell:~/nlp (uconn-engr)$
Create a Python virtual environment to isolate the dependencies:
Python virtual environments are useful for a number of reasons, including:
Separating dependencies
Virtual environments keep packages for different projects isolated so
they don't conflict. For example, if you're working on two projects
that require different versions of a package, you can create a virtual
environment for each project to keep their versions separate.
Ensuring consistent package versions
Virtual environments help ensure that the correct package versions
are used each time the software runs.
virtualenv venv-language
john_iacovacci1@cloudshell:~/nlp (uconn-engr)$ virtualenv venv-language
created virtual environment CPython3.12.3.final.0-64 in 2203ms
creator CPython3Posix(dest=/home/john_iacovacci1/nlp/venv-language, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, via=copy, app_data_dir=/home/john_iacovacci1/.local/share/virtualenv)
added seed packages: pip==24.2
activators BashActivator,CShellActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
john_iacovacci1@cloudshell:~/nlp (uconn-engr)$
Activate the virtual environment:
source venv-language/bin/activate
john_iacovacci1@cloudshell:~/nlp (uconn-engr)$ source venv-language/bin/activate
(venv-language) john_iacovacci1@cloudshell:~/nlp (uconn-engr)$
To stop using the virtual environment and go back to your system Python
version, you can use the deactivate command.
Install IPython, Pandas, and the Natural Language API client library:
pip install ipython pandas tabulate google-cloud-language
(venv-language) john_iacovacci1@cloudshell:~/nlp (uconn-engr)$ pip install ipython pandas tabulate google-cloud-language
You should see something like this:
...
Installing collected packages: ... pandas ... ipython ... google-cloud-language
Successfully installed ... google-cloud-language-2.11.0 ...
Now, you're ready to use the Natural Language API client library!
If you're setting up your own Python development environment outside of
Cloud Shell, you can follow these guidelines.
In the next steps, you'll use an interactive Python interpreter called IPython, which you installed in the previous step. Start a session by running ipython in Cloud Shell:
ipython
(venv-language) john_iacovacci1@cloudshell:~/nlp (uconn-engr)$ ipython
Python 3.12.3 (main, Sep 11 2024, 14:17:37) [GCC 13.2.0]
Type 'copyright', 'credits' or 'license' for more information
IPython 8.29.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
4. Sentiment analysis
Sentiment analysis inspects the given text and identifies the prevailing emotional
opinions within the text, especially to determine expressed sentiments as positive,
negative, or neutral, both at the sentence and the document levels.
It is performed with the analyze_sentiment method which returns an AnalyzeSentimentResponse.
Copy the following code into your IPython session:
====================================================================
from google.cloud import language
def analyze_text_sentiment(text: str) -> language.AnalyzeSentimentResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.analyze_sentiment(document=document)
def show_text_sentiment(response: language.AnalyzeSentimentResponse):
import pandas as pd
columns = ["score", "sentence"]
data = [(s.sentiment.score, s.text.content) for s in response.sentences]
df_sentence = pd.DataFrame(columns=columns, data=data)
sentiment = response.document_sentiment
columns = ["score", "magnitude", "language"]
data = [(sentiment.score, sentiment.magnitude, response.language)]
df_document = pd.DataFrame(columns=columns, data=data)
format_args = dict(index=False, tablefmt="presto", floatfmt="+.1f")
print(f"At sentence level:\n{df_sentence.to_markdown(**format_args)}")
print()
print(f"At document level:\n{df_document.to_markdown(**format_args)}")
========================================================
Perform an analysis:
========================================================
# Input
text = """
Python is a very readable language, which makes it easy to understand and maintain code.
It's simple, very flexible, easy to learn, and suitable for a wide variety of tasks.
One disadvantage is its speed: it's not as fast as some other programming languages.
"""
# Send a request to the API
analyze_sentiment_response = analyze_text_sentiment(text)
# Show the results
show_text_sentiment(analyze_sentiment_response)At sentence level:
score | sentence
---------+------------------------------------------------------------------------------------------
+0.8 | Python is a very readable language, which makes it easy to understand and maintain code.
+0.9 | It's simple, very flexible, easy to learn, and suitable for a wide variety of tasks.
-0.4 | One disadvantage is its speed: it's not as fast as some other programming languages.
At document level:
score | magnitude | language
---------+-------------+------------
+0.4 | +2.2 | en
In [6]:
Take a moment to test your own sentences.
Information on which languages are supported by the Natural Language API,
see Language Support
The score of the sentiment ranges between -1.0 (negative) and +1.0 (positive)
and corresponds to the overall sentiment from the given information.
The magnitude of the sentiment ranges from 0.0 to +inf and indicates the overall
strength of sentiment from the given information.
The more information provided, the higher the magnitude.
For more information on how to interpret the score and magnitude sentiment
values included in the analysis, see Interpreting sentiment analysis values.
Each API response returns the document automatically-detected language
(in ISO-639-1). It is shown here and will be skipped in the next analysis examples.
Summary
In this step, you were able to perform sentiment analysis on a string of text!
5. Entity analysis
Entity analysis inspects the given text for known entities (proper nouns such as
public figures, landmarks, etc.), and returns information about those entities.
It is performed with the analyze_entities method which returns an AnalyzeEntitiesResponse.
Copy the following code into your IPython session:
=====================================================
from google.cloud import language
def analyze_text_entities(text: str) -> language.AnalyzeEntitiesResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.analyze_entities(document=document)
def show_text_entities(response: language.AnalyzeEntitiesResponse):
import pandas as pd
columns = ("name", "type", "salience", "mid", "wikipedia_url")
data = (
(
entity.name,
entity.type_.name,
entity.salience,
entity.metadata.get("mid", ""),
entity.metadata.get("wikipedia_url", ""),
)
for entity in response.entities
)
df = pd.DataFrame(columns=columns, data=data)
print(df.to_markdown(index=False, tablefmt="presto", floatfmt=".0%"))
======================================================
Perform an analysis:
# Input
text = """Guido van Rossum is best known as the creator of Python,
which he named after the Monty Python comedy troupe.
He was born in Haarlem, Netherlands.
"""
# Send a request to the API
analyze_entities_response = analyze_text_entities(text)
# Show the results
show_text_entities(analyze_entities_response)
You should see an output like the following:
name | type | salience | mid | wikipedia_url
------------------+--------------+------------+-----------+-------------------------------------------------------------
Guido van Rossum | PERSON | 50% | /m/01h05c | https://en.wikipedia.org/wiki/Guido_van_Rossum
Python | ORGANIZATION | 38% | /m/05z1_ | https://en.wikipedia.org/wiki/Python_(programming_language)
creator | PERSON | 5% | |
Monty Python | PERSON | 3% | /m/04sd0 | https://en.wikipedia.org/wiki/Monty_Python
comedy troupe | PERSON | 2% | |
Haarlem | LOCATION | 1% | /m/0h095 | https://en.wikipedia.org/wiki/Haarlem
Netherlands | LOCATION | 1% | /m/059j2 | https://en.wikipedia.org/wiki/Netherlands
Take a moment to test your own sentences mentioning other entities.
For information on which languages are supported by this method, see Language Support.
The type of the entity is an enum that lets you classify or differentiate entities. For example, this can help distinguish the similarly named entities "T.E. Lawrence" (a PERSON) from "Lawrence of Arabia" (the film, tagged as a WORK_OF_ART). See Entity.Type.
The entity salience indicates the importance or relevance of this entity to the entire document text. This score can assist information retrieval and summarization by prioritizing salient entities. Scores closer to 0.0 are less important, while scores closer to 1.0 are highly important.
For more information, see Entity analysis.
You can also combine both entity analysis and sentiment analysis with the analyze_entity_sentiment method. See Entity sentiment analysis.
Summary
In this step, you were able to perform entity analysis!
6. Syntax analysis
Syntax analysis extracts linguistic information, breaking up the given text into
a series of sentences and tokens (generally based on word boundaries),
providing further analysis on those tokens. It is performed with the analyze_syntax method which returns an AnalyzeSyntaxResponse.
Copy the following code into your IPython session:
from typing import Optional
from google.cloud import language
def analyze_text_syntax(text: str) -> language.AnalyzeSyntaxResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.analyze_syntax(document=document)
def get_token_info(token: Optional[language.Token]) -> list[str]:
parts = [
"tag",
"aspect",
"case",
"form",
"gender",
"mood",
"number",
"person",
"proper",
"reciprocity",
"tense",
"voice",
]
if not token:
return ["token", "lemma"] + parts
text = token.text.content
lemma = token.lemma if token.lemma != token.text.content else ""
info = [text, lemma]
for part in parts:
pos = token.part_of_speech
info.append(getattr(pos, part).name if part in pos else "")
return info
def show_text_syntax(response: language.AnalyzeSyntaxResponse):
import pandas as pd
tokens = len(response.tokens)
sentences = len(response.sentences)
columns = get_token_info(None)
data = (get_token_info(token) for token in response.tokens)
df = pd.DataFrame(columns=columns, data=data)
# Remove empty columns
empty_columns = [col for col in df if df[col].eq("").all()]
df.drop(empty_columns, axis=1, inplace=True)
print(f"Analyzed {tokens} token(s) from {sentences} sentence(s):")
print(df.to_markdown(index=False, tablefmt="presto"))
Perform an analysis:
# Input
text = """Guido van Rossum is best known as the creator of Python.
He was born in Haarlem, Netherlands.
"""
# Send a request to the API
analyze_syntax_response = analyze_text_syntax(text)
# Show the results
show_text_syntax(analyze_syntax_response)
You should see an output like the following:
Analyzed 20 token(s) from 2 sentence(s):
token | lemma | tag | case | gender | mood | number | person | proper | tense | voice
-------------+---------+-------+------------+-----------+------------+----------+----------+----------+---------+---------
Guido | | NOUN | | | | SINGULAR | | PROPER | |
van | | NOUN | | | | SINGULAR | | PROPER | |
Rossum | | NOUN | | | | SINGULAR | | PROPER | |
is | be | VERB | | | INDICATIVE | SINGULAR | THIRD | | PRESENT |
best | well | ADV | | | | | | | |
known | know | VERB | | | | | | | PAST |
as | | ADP | | | | | | | |
the | | DET | | | | | | | |
creator | | NOUN | | | | SINGULAR | | | |
of | | ADP | | | | | | | |
Python | | NOUN | | | | SINGULAR | | PROPER | |
. | | PUNCT | | | | | | | |
He | | PRON | NOMINATIVE | MASCULINE | | SINGULAR | THIRD | | |
was | be | VERB | | | INDICATIVE | SINGULAR | THIRD | | PAST |
born | bear | VERB | | | | | | | PAST | PASSIVE
in | | ADP | | | | | | | |
Haarlem | | NOUN | | | | SINGULAR | | PROPER | |
, | | PUNCT | | | | | | | |
Netherlands | | NOUN | | | | SINGULAR | | PROPER | |
. | | PUNCT | | | | | | | |
Take a moment to test your own sentences with other syntactic structures.
Extracting syntax information has multiple advantages. One is to extract lemmas.
A lemma contains the "root" word upon which this token is based,
which allows you to manage words with their canonical forms.
If you dive deeper into the response insights, you'll also find the relationships
between the tokens. Here is a visual interpretation showing the complete syntax
analysis for this example, a screenshot from the online Natural Language demo:
For more information, see the following:
AnalyzeSyntaxResponse
Language Support
Syntactic analysis
Morphology & Dependency Trees
Summary
In this step, you were able to perform syntax analysis!
7. Content classification
Content classification analyzes a document and returns a list of content
categories that apply to the text found in the document. It is performed
with the classify_text method which returns a ClassifyTextResponse.
Copy the following code into your IPython session:
from google.cloud import language
def classify_text(text: str) -> language.ClassifyTextResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.classify_text(document=document)
def show_text_classification(text: str, response: language.ClassifyTextResponse):
import pandas as pd
columns = ["category", "confidence"]
data = ((category.name, category.confidence) for category in response.categories)
df = pd.DataFrame(columns=columns, data=data)
print(f"Text analyzed:\n{text}")
print(df.to_markdown(index=False, tablefmt="presto", floatfmt=".0%"))
Perform an analysis:
# Input
text = """Python is an interpreted, high-level, general-purpose programming language.
Created by Guido van Rossum and first released in 1991, Python's design philosophy
emphasizes code readability with its notable use of significant whitespace.
"""
# Send a request to the API
classify_text_response = classify_text(text)
# Show the results
show_text_classification(text, classify_text_response)
You should see an output like the following:
Text analyzed:
Python is an interpreted, high-level, general-purpose programming language.
Created by Guido van Rossum and first released in 1991, Python's design philosophy
emphasizes code readability with its notable use of significant whitespace.
category | confidence
--------------------------------------+--------------
/Computers & Electronics/Programming | 99%
/Science/Computer Science | 99%
Take a moment to test your own sentences relating to other categories.
Note that you must supply a text block (document) with at least twenty tokens
(words and punctuation signs).
For more information, see the following docs:
ClassifyTextResponse
Language Support
Content Classification
Summary
In this step, you were able to perform content classification!
8. Text moderation
Powered by Google's latest PaLM 2 foundation model, text moderation identifies
a wide range of harmful content, including hate speech, bullying, and sexual harassment.
It is performed with the moderate_text method which returns a ModerateTextResponse.
Copy the following code into your IPython session:
from google.cloud import language
def moderate_text(text: str) -> language.ModerateTextResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.moderate_text(document=document)
def show_text_moderation(text: str, response: language.ModerateTextResponse):
import pandas as pd
def confidence(category: language.ClassificationCategory) -> float:
return category.confidence
columns = ["category", "confidence"]
categories = sorted(response.moderation_categories, key=confidence, reverse=True)
data = ((category.name, category.confidence) for category in categories)
df = pd.DataFrame(columns=columns, data=data)
print(f"Text analyzed:\n{text}")
print(df.to_markdown(index=False, tablefmt="presto", floatfmt=".0%"))
Perform an analysis:
# Input
text = """I have to read Ulysses by James Joyce.
I'm a little over halfway through and I hate it.
What a pile of garbage!
"""
# Send a request to the API
response = moderate_text(text)
# Show the results
show_text_moderation(text, response)
You should see an output like the following:
Text analyzed:
I have to read Ulysses by James Joyce.
I'm a little over halfway through and I hate it.
What a pile of garbage!
category | confidence
-----------------------+--------------
Toxic | 67%
Insult | 58%
Profanity | 53%
Violent | 48%
Illicit Drugs | 29%
Religion & Belief | 27%
Politics | 22%
Death, Harm & Tragedy | 21%
Finance | 18%
Derogatory | 14%
Firearms & Weapons | 11%
Health | 10%
Legal | 10%
War & Conflict | 7%
Public Safety | 5%
Sexual | 4%
Take a moment to test your own sentences.
For more information, see the following docs:
ModerateTextResponse
Language Support
Moderating Text
Summary
In this step, you were able to perform text moderation!

No comments:
Post a Comment