
NLP Example Explained
Overview
In this codelab, you will focus on using the Natural Language API with Python. You will learn how to perform sentiment analysis, entity analysis, syntax analysis, and content classification.
What you'll learn
How to use Cloud Shell
How to enable the Natural Language API
How to authenticate API requests
How to install the client library for Python
How to perform sentiment analysis
How to perform entity analysis
How to perform syntax analysis
How to perform content classification
What you'll need
2. Setup and requirements
Self-paced environment setup
Sign in to Cloud Console and create a new project or reuse an existing one. (If you don't already have a Gmail or G Suite account, you must create one.)
Note: You can easily access Cloud Console by memorizing its URL, which is console.cloud.google.com.



Remember the project ID, a unique name across all Google Cloud projects (the name above has already been taken and will not work for you, sorry!). It will be referred to later in this codelab as PROJECT_ID.
Note: If you're using a Gmail account, you can leave the default location set to No organization. If you're using a G Suite account, then choose a location that makes sense for your organization.
Next, you'll need to enable billing in Cloud Console in order to use Google Cloud resources.
Running through this codelab shouldn't cost much, if anything at all. Be sure to to follow any instructions in the "Cleaning up" section which advises you how to shut down resources so you don't incur billing beyond this tutorial. New users of Google Cloud are eligible for the $300USD Free Trial program.
Start Cloud Shell
While Google Cloud can be operated remotely from your laptop, in this codelab you will be using Cloud Shell, a command line environment running in the Cloud.
Activate Cloud Shell
From the Cloud Console, click Activate Cloud Shell .


If you've never started Cloud Shell before, you'll be presented with an intermediate screen (below the fold) describing what it is. If that's the case, click Continue (and you won't ever see it again). Here's what that one-time screen looks like:
It should only take a few moments to provision and connect to Cloud Shell.

This virtual machine is loaded with all the development tools you'll need. It offers a persistent 5GB home directory and runs in Google Cloud, greatly enhancing network performance and authentication. Much, if not all, of your work in this codelab can be done with simply a browser or your Chromebook.
Once connected to Cloud Shell, you should see that you are already authenticated and that the project is already set to your project ID.
Run the following command in Cloud Shell to confirm that you are authenticated:
gcloud auth list
Command output
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Note: The gcloud command-line tool is the powerful and unified command-line tool in Google Cloud. It comes preinstalled in Cloud Shell. You will notice its support for tab completion. For more information, see gcloud command-line tool overview.
gcloud config list project
Command output
[core]
project = <PROJECT_ID>
If it is not, you can set it with this command:
gcloud config set project <PROJECT_ID>
Command output
Updated property [core/project].
3. Enable the API
Before you can begin using the Natural Language API, you must enable the API. Using Cloud Shell, you can enable the API with the following command:
gcloud services enable language.googleapis.com
Note: In case of error, go back to the previous step and check your setup.
4. Authenticate API requests
In order to make requests to the Natural Language API, you need to use a Service Account. A Service Account belongs to your project and it is used by the Python client library to make Natural Language API requests. Like any other user account, a service account is represented by an email address. In this section, you will use the Cloud SDK to create a service account and then create credentials you will need to authenticate as the service account.
First, set a PROJECT_ID environment variable:
export PROJECT_ID=$(gcloud config get-value core/project)
Next, create a new service account to access the Natural Language API by using:
gcloud iam service-accounts create my-nl-sa --display-name "my nl service account"
Next, create credentials that your Python code will use to login as your new service account. Create and save these credentials as a ~/key.json JSON file by using the following command:
gcloud iam service-accounts keys create ~/key.json --iam-account my-nl-sa@${PROJECT_ID}.iam.gserviceaccount.com
Finally, set the GOOGLE_APPLICATION_CREDENTIALS environment variable, which is used by the Natural Language API Python library, covered in the next step, to find your credentials. The environment variable should be set to the full path of the credentials JSON file you created, by using:
export GOOGLE_APPLICATION_CREDENTIALS=~/key.json
Note: You can read more about authenticating to a Google Cloud API.
5. Install the client library
You're going to use the Google Cloud Python client library, which should already be installed in your Cloud Shell environment. You can read more about Google Cloud Python services here.
Check that the client library is already installed:
pip3 freeze | grep google-cloud-language
You should see something similar to:
google-cloud-language==2.0.0
Note: If you're setting up your own Python development environment, you can follow these guidelines. You can then install (or update) the Natural Language API client library with pip3:
pip3 install --user --upgrade google-cloud-language
...
Successfully installed google-cloud-language-2.0.0
Now, you're ready to use the Natural Language API!
6. Start Interactive Python
In this tutorial, you'll use an interactive Python interpreter called IPython, which is preinstalled in Cloud Shell. Start a session by running ipython in Cloud Shell:
ipython
You should see something like this:
Python 3.7.3 (default, Jul 25 2020, 13:03:44)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.18.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
Note: If needed, you can quit your IPython session with the exit command.
7. Sentiment analysis
In this section, you will perform Sentiment Analysis on a string and find out the Score and Magnitude using the Natural Language API.
The Score of the sentiment ranges between -1.0 (negative) and 1.0 (positive) and corresponds to the overall sentiment from the given information.
The Magnitude of the sentiment ranges from 0.0 to +infinity and indicates the overall strength of sentiment from the given information. The more information that is provided the higher the magnitude.
Copy the following code into your IPython session:
======================================================================
from google.cloud import language
def analyze_text_sentiment(text):
client = language.LanguageServiceClient()
document = language.Document(content=text, type_=language.Document.Type.PLAIN_TEXT)
response = client.analyze_sentiment(document=document)
sentiment = response.document_sentiment
results = dict(
text=text,
score=f"{sentiment.score:.1%}",
magnitude=f"{sentiment.magnitude:.1%}",
)
for k, v in results.items():
print(f"{k:10}: {v}")
=====================================================================
Call the function:
text = "Guido van Rossum is great!"
analyze_text_sentiment(text)
You should see the following output:
text : Guido van Rossum is great!
score : 90.0%
magnitude : 90.0%
Take a moment to test your own sentences.
Summary
In this step, you were able to perform Sentiment Analysis on a string of text and printed out its score and magnitude. Read more about Sentiment Analysis.
8. Entity analysis
Entity Analysis inspects the given information for entities by searching for proper nouns such as public figures, landmarks, etc., and returns information about those entities.
Copy the following code into your IPython session:
==================================================
from google.cloud import language
def analyze_text_entities(text):
client = language.LanguageServiceClient()
document = language.Document(content=text, type_=language.Document.Type.PLAIN_TEXT)
response = client.analyze_entities(document=document)
for entity in response.entities:
print("=" * 80)
results = dict(
name=entity.name,
type=entity.type_.name,
salience=f"{entity.salience:.1%}",
wikipedia_url=entity.metadata.get("wikipedia_url", "-"),
mid=entity.metadata.get("mid", "-"),
)
for k, v in results.items():
print(f"{k:15}: {v}")
==========================================================================
Call the function:
text = "Guido van Rossum is great, and so is Python!"
analyze_text_entities(text)
You should see the following output:
================================================================================
name : Guido van Rossum
type : PERSON
salience : 65.8%
wikipedia_url : https://en.wikipedia.org/wiki/Guido_van_Rossum
mid : /m/01h05c
================================================================================
name : Python
type : ORGANIZATION
salience : 34.2%
wikipedia_url : https://en.wikipedia.org/wiki/Python_(programming_language)
mid : /m/05z1_
In [1]: from google.cloud import language ...: def analyze_text_entities(text): ...: client = language.LanguageServiceClient() ...: document = language.Document(content=text, type_=language.Document.Type.PLAIN_TEXT) ...: response = client.analyze_entities(document=document) ...: for entity in response.entities: ...: print("=" * 80) ...: results = dict( ...: name=entity.name, ...: type=entity.type_.name, ...: salience=f"{entity.salience:.1%}", ...: wikipedia_url=entity.metadata.get("wikipedia_url", "-"), ...: mid=entity.metadata.get("mid", "-"), ...: ) ...: for k, v in results.items(): ...: print(f"{k:15}: {v}") ...: ...: In [2]: text = "Guido van Rossum is great, and so is Python!" In [3]: analyze_text_entities(text) ================================================================================ name : Guido van Rossum type : PERSON salience : 65.8% wikipedia_url : https://en.wikipedia.org/wiki/Guido_van_Rossum mid : /m/01h05c ================================================================================ name : Python type : ORGANIZATION salience : 34.2%
Take a moment to test your own sentences mentioning other entities.
Summary
In this step, you were able to perform Entity Analysis on a string of text and printed out its entities. Read more about Entity Analysis.
9. Syntax analysis
Syntactic Analysis extracts linguistic information, breaking up the given text into a series of sentences and tokens (generally, word boundaries), providing further analysis on those tokens.
This example will print out the number of sentences, tokens, and provide the part of speech for each token.
Copy the following code into your IPython session:
========================================
from google.cloud import language
def analyze_text_syntax(text):
client = language.LanguageServiceClient()
document = language.Document(content=text, type_=language.Document.Type.PLAIN_TEXT)
response = client.analyze_syntax(document=document)
fmts = "{:10}: {}"
print(fmts.format("sentences", len(response.sentences)))
print(fmts.format("tokens", len(response.tokens)))
for token in response.tokens:
print(fmts.format(token.part_of_speech.tag.name, token.text.content))======================================================
Call the function:
text = "Guido van Rossum is great!"
analyze_text_syntax(text)
You should see the following output:
sentences : 1
tokens : 6
NOUN : Guido
NOUN : van
NOUN : Rossum
VERB : is
ADJ : great
PUNCT : !
In [1]: from google.cloud import language ...: ...: ...: def analyze_text_syntax(text): ...: client = language.LanguageServiceClient() ...: document = language.Document(content=text, type_=language.Document.Type.PLAIN_TEXT) ...: ...: response = client.analyze_syntax(document=document) ...: ...: fmts = "{:10}: {}" ...: print(fmts.format("sentences", len(response.sentences))) ...: print(fmts.format("tokens", len(response.tokens))) ...: for token in response.tokens: ...: print(fmts.format(token.part_of_speech.tag.name, token.text.content)) ...: In [2]: text = "Guido van Rossum is great!" In [3]: analyze_text_syntax(text) sentences : 1 tokens : 6 NOUN : Guido NOUN : van NOUN : Rossum VERB : is ADJ : great PUNCT : !
Take a moment to test your own sentences with other syntactic structures.
Here is a visual interpretation showing the complete syntactic analysis:
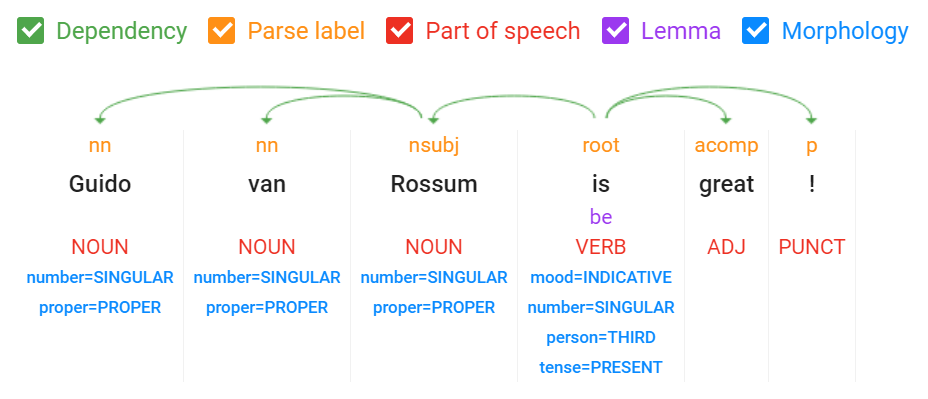
Note: You can create your own parse trees with the Natural Language demo available here: https://cloud.google.com/natural-language/.
Summary
In this step, you were able to perform Syntax Analysis on a simple string of text and printed out the number of sentences, number of tokens, and linguistic information for each token. Read more about Syntax Analysis.
10. Content classification
Content Classification analyzes a document and return a list of content categories that apply to the text found in the document.
This example will print out the categories that apply to a description of the Python language.
Copy the following code into your IPython session:
==========================
from google.cloud import language
def classify_text(text):
client = language.LanguageServiceClient()
document = language.Document(content=text, type_=language.Document.Type.PLAIN_TEXT)
response = client.classify_text(document=document)
for category in response.categories:
print("=" * 80)
print(f"category : {category.name}")
print(f"confidence: {category.confidence:.0%}")=================
Call the function:
text = (
"Python is an interpreted, high-level, general-purpose programming language. "
"Created by Guido van Rossum and first released in 1991, "
"Python's design philosophy emphasizes code readability "
"with its notable use of significant whitespace."
)
classify_text(text)
You should see the following output:
================================================================================
category : /Computers & Electronics/Programming
confidence: 99%
================================================================================
category : /Science/Computer Science
confidence: 99%
Take a moment to test your own sentences relating to other categories. A complete list of content categories can be found here.
Note: You must supply a text block (document) with at least twenty tokens (words).
Summary
In this step, you were able to perform Content Classification on a string of text and printed out the related categories. Read more about Content Classification.
Authenticate API requests
In order to make requests to the Natural Language API, you need to use a Service Account. A Service Account belongs to your project and it is used by the Python client library to make Natural Language API requests. Like any other user account, a service account is represented by an email address. In this section, you will use the Cloud SDK to create a service account and then create credentials you will need to authenticate as the service account.
First, set a PROJECT_ID environment variable:
export PROJECT_ID=$(gcloud config get-value core/project)
Next, create a new service account to access the Natural Language API by using:
gcloud iam service-accounts create my-nl-sa \
--display-name "my nl service account"
Next, create credentials that your Python code will use to login as your new service account. Create and save these credentials as a ~/key.json JSON file by using the following command:
gcloud iam service-accounts keys create ~/key.json \
--iam-account my-nl-sa@${PROJECT_ID}.iam.gserviceaccount.com
Finally, set the GOOGLE_APPLICATION_CREDENTIALS environment variable, which is used by the Natural Language API Python library, covered in the next step, to find your credentials. The environment variable should be set to the full path of the credentials JSON file you created, by using:
export GOOGLE_APPLICATION_CREDENTIALS=~/key.json
pip3 install --user --upgrade google-cloud-language
Sentiment.pl
from google.cloud import language
def analyze_text_sentiment(text):
client = language.LanguageServiceClient()
document = language.Document(content=text, type_=language.Document.Type.PLAIN_TEXT)
response = client.analyze_sentiment(document=document)
sentiment = response.document_sentiment
results = dict(
text=text,
score=f"{sentiment.score:.1%}",
magnitude=f"{sentiment.magnitude:.1%}",
)
for k, v in results.items():
print(f"{k:10}: {v}")
Natural Language API application, using an analyzeSentiment request, which performs sentiment analysis on text. Sentiment analysis attempts to determine the overall attitude (positive or negative) and is represented by numerical score and magnitude values.
It is recommended that you have the latest version of Python, pip, and virtualenv installed on your system
basic Natural Language API application, using an analyzeSentiment request, which performs sentiment analysis on text.
import argparse
from google.cloud import language_v1
def print_result(annotations):
score = annotations.document_sentiment.score
magnitude = annotations.document_sentiment.magnitude
for index, sentence in enumerate(annotations.sentences):
sentence_sentiment = sentence.sentiment.score
print(
"Sentence {} has a sentiment score of {}".format(index, sentence_sentiment)
)
print(
"Overall Sentiment: score of {} with magnitude of {}".format(score, magnitude)
)
return 0
def analyze(movie_review_filename):
"""Run a sentiment analysis request on text within a passed filename."""
client = language_v1.LanguageServiceClient()
with open(movie_review_filename, "r") as review_file:
# Instantiates a plain text document.
content = review_file.read()
document = language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT)
annotations = client.analyze_sentiment(request={'document': document})
# Print the results
print_result(annotations)
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description=__doc__, formatter_class=argparse.RawDescriptionHelpFormatter
)
parser.add_argument(
"movie_review_filename",
help="The filename of the movie review you'd like to analyze.",
)
args = parser.parse_args()
analyze(args.movie_review_filename)
We import argparse, a standard library, to allow the application to accept input filenames as arguments.
Running your application
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description=__doc__, formatter_class=argparse.RawDescriptionHelpFormatter
)
parser.add_argument(
"movie_review_filename",
help="The filename of the movie review you'd like to analyze.",
)
args = parser.parse_args()
analyze(args.movie_review_filename)
Here, we simply parse the passed argument for the text filename and pass it to the analyze() function.
Authenticating to the API
Before communicating with the Natural Language API service, you need to authenticate your service using previously acquired credentials. Within an application, the simplest way to obtain credentials is to use Application Default Credentials (ADC
Making the request
Now that our Natural Language API service is ready, we can access the service by calling the analyze_sentiment method of the LanguageServiceClient instance.
The client library encapsulates the details for requests and responses to the API. See the Natural Language API Reference for complete information on the specific structure of such a request.
def analyze(movie_review_filename):
"""Run a sentiment analysis request on text within a passed filename."""
client = language_v1.LanguageServiceClient()
with open(movie_review_filename, "r") as review_file:
# Instantiates a plain text document.
content = review_file.read()
document = language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT)
annotations = client.analyze_sentiment(request={'document': document})
# Print the results
print_result(annotations)
This code snippet performs the following tasks:
Instantiates a LanguageServiceClient instance as the client.
Reads the filename containing the text data into a variable.
Instantiates a Document object with the contents of the file.
Calls the client's analyze_sentiment method.
def print_result(annotations):
score = annotations.document_sentiment.score
magnitude = annotations.document_sentiment.magnitude
for index, sentence in enumerate(annotations.sentences):
sentence_sentiment = sentence.sentiment.score
print(
"Sentence {} has a sentiment score of {}".format(index, sentence_sentiment)
)
print(
"Overall Sentiment: score of {} with magnitude of {}".format(score, magnitude)
)
return 0

No comments:
Post a Comment